在如今深度学习大爆发的时代,相关的硬件平台也在百花齐放,既有英伟达和谷歌这样的科技巨头,也有地平线机器人和 Graphcore 等创业公司——它们都各自提出了自己的解决方案。近日,多家公司的技术顾问 Matt Hurd 在其博客上发表了一篇全面评点各种神经网络硬件平台的长文,机器之心对本文进行了编译介绍。 这是我几周前做的一个传统的 90 年代风格的性别识别神经网络的很好的隐藏节点。

一个简单的性别识别器网络中的 90 年代风格的隐藏节点图像 我的硕士项目是一种类似级联相关(cascade correlation)的神经网络 Multi-rate Optimising Order Statistic Equaliser(MOOSE:多速率优化顺序统计均衡器),可用于日内的 Bund(国库债券产品)交易。MOOSE 曾经是为获取高速的 LEO 卫星信号(McCaw 的 Teledesic)而设计的一点成果,后来在从 LIFFE 迁移到 DTB 时将目标转向了 Bund。作为一家投资银行的职业交易员,我可以购买很好的工具。我有那时候世界上最快的计算机:一个 IBM MicroChannel dual Pentium Pro 200MHz 处理器外加带有几 MB RAM 的 SCSI。在 1994 年那会儿,将 800,000 个数据点输入到我的 C++ stream/dag 处理器中看上去就像是黑魔法。有限差分方法让我可以做许多 O(1) 增量线性回归这样的运算,以获得 1000 倍的加速。那时候这看起来已经很好了。现在,你的手机都能嘲笑我的大方向。 那时候,在神经网络领域有很多研究。倒不是说它有过人的生产力,只是因为有用。读到 Lindsay Fortado 和 Robin Wigglesworth 的 FT 文章《Machine learning set to shake up equity hedge funds》中 Eric Schmidt 关于机器学习和交易的看法,还真有点让人高兴: Eric Schmidt 是谷歌母公司 Alphabet 的执行董事长,他上周对一众对冲基金经理说他相信在 50 年内,所有交易都会有计算机解读数据和市场信号。 「我期待出现在交易方面做机器学习的创业公司,看看我描述的这种模式识别能否比数据分析专家的传统线性回归算法做得更好。」他补充说,「我这个行业内的许多人都认为这注定将成为一种新的交易形式。」
老朋友 Eric,我在 90 年代早期就已经算是迟到了,你真是有点后知后觉。 好吧,现在情况已经不同了。我喜欢思考它,并喜欢将神经网络的这次新复兴称为感知时代(The Age of Perception)。这并不是智能,只是擅长模式而已。它仍然无力应对语言歧义。它还要一些时间才能理解基本的价值和概念,从而形成深刻的金融理解。 深度学习既被夸大了,也被低估了。这不是智能,但会有助于帮我们实现智能。一些人将其夸大为将会给我们带来替代人的类人机器的人工智能突破。我们仍然还受困于常识以及用于推理的简单文本中的歧义。我们还有很长的路要走。相对简单的规划算法和启发式方法以及基于神奇的深度学习的视觉、声音、文本、雷达等等的感知能力将会带来深刻的影响,就像是每个人和他们的狗现在理解的那样。所以我叫它「感知时代」。
就好像是我们口袋里的超级计算机突然有了眼睛,并且快速适应了真实世界所带来的闪光性致盲。 深度学习将会带来巨大的影响,并且将会改变这颗行星上全人类的生活方式。但我们低估了其对我们的危险。不,我们不会和能激起或挑战我们最深刻的思想的深度图灵对话者约会——还不会。这将不可避免地到来,但在可见的未来里还不可见。借助语音、文本和 Watson 那样的数据库的智能代理可以实现非常先进的 Eliza,但不会更先进了。自动化运输、食物生产、建筑、协助家事将会极大地改变人们的生活方式和不动产的价值。 除了这些泛泛之谈,本文的目的是收集一些关于芯片的思想见解——它们驱动着当前的神经网络革命。其中很多见解都不是最为激动人心的,但这对我来说是一个有用的锻炼。
神经网络硬件 与 20 年前相比,今天的神经处理方法并没有很大不同。深度更多的是一个品牌,而不是一项差异。激活函数已经得到了简化,以更好地适配硬件。主要的成功之处在于我们有了更多数据,对如何初始化权重、处理许多层、并行化和提升鲁棒性也有了更好的理解,其中要用到像是 dropout 这样的技术。1980 年的 Neocognitron 架构与今天的深度学习器或 CNN 并没有显著差异,但 Yann LeCun 让它具备了学习能力。 在 90 年代那会儿也有很多神经硬件平台,比如 CNAPS(1990),它带有 64 个处理单元和 256kB 内存,可以在 8/16 位条件下达到 1.6 GCPS 的速度(CPS 是指每秒连接次数/ connections per second)或在 1 位条件下达到 12.8 GCPS 的速度。你可以在《神经硬件概述(Overview of neural hardware)》[Heemskerk, 1995, draft] 中读到 Synapse-1、CNAPS、SNAP、CNS Connectionist Supercomputer、Hitachi WSI、My-Neupower、LNeuro 1.0、UTAK1、GNU(通用神经单元/General Neural Unit)Implementation、UCL、Mantra 1、Biologically-Inspired Emulator、INPG Architecture、BACHUS 和 ZISC036。 阅读地址:https://pdfs.semanticscholar.org/5841/73aa4886f87da4501571957c2b14a8fb9069.pdf 好吧,东西还真多,但实际上还排除了软件和加速器板/CPU 组合,比如 ANZA plus、SAIC SIGMA-1、NT6000、Balboa 860 协处理器、Ni1000 识别加速器硬件(英特尔)、IBM NEP、NBC、Neuro Turbo I、Neuro Turbo II、WISARD、Mark II & IV、Sandy/8、GCN(索尼)、Topsi、BSP400(400 微处理器)、DREAM Machine、RAP、COKOS、REMAP、通用并行神经计算机(General Purpose Parallel Neurocomputer)、TI NETSIM 和 GeNet。另外还有一些模拟和混合模拟的实现,包括英特尔的电气式可训练模拟神经网络(801770NX)。你懂我要表达的意思了,那时候的东西还真是多。 这在 1994 年迎来了一次爆发: 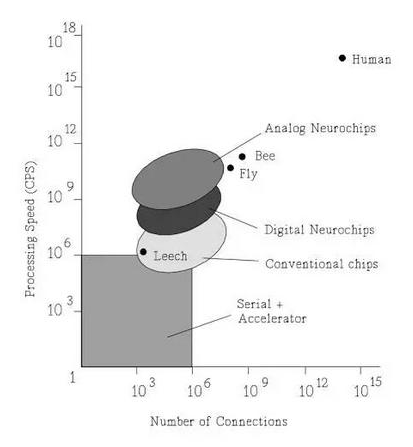
乐观的摩尔定律告诉我们,TeraCPS 即将实现: 「未来十年,微电子很可能将继续主导神经网络实现的领域。如果进展和过去进步得一样快,那就意味着神经计算机的性能将会增长大约 2 个数量级。因此,神经计算机将会接近 TeraCPS(10^12 CPS)的性能。由 100 万个节点(每个节点有大约 1000 个输入)组成的网络可以达到大脑的计算速度(100-1000 Hz)。这将能为实验合理巨大的网络提供良好的机会。」 由于 Minsky 和 Papert 对隐藏层的不正确简单概括,打击了 Rosenblatt 的感知器梦想并最终导致了他不幸的死亡,神经网络研究遭遇了第一个冬天,研究资金被残酷地撤销了。1995 年,又出现了另一次神经网络冬天,尽管那时候我其实并不知道。作为温水锅里的一只青蛙,我没有注意到正在加热。第二个冬天的主要原因是缺乏激动人心的进展,让人们普遍感到无聊了。 到了 2012 年,多亏了 Geoffrey Hinton 的冬季生存技能,多伦多大学基于 AlexNet 开发的 SuperVision 在 ImageNet 处理上实现了极大的提升,第二个神经网络冬天也由此终结了。之后谷歌的 LeNet Inception 模型在 2014 年打破了它的记录。所以据我估计,感知时代始于 2012 年。将它记在你的日历里面吧,五年已经过去了。 谷歌在几千台普通机器上进行了出色的并行 CPU 有损更新研究。吴恩达教授和他的朋友们让数十台 GPU 就能完成数千台 CPU 的工作,从而让规模化成为了可能。因此,我们从需要很好的资助的神经处理前景中解放了出来。好吧,或多或少吧,现在最先进的网络有时候需要数千台 GPU 或专用芯片。
。 (本文来源网络整理,目的是传播有用的信息和知识,如有侵权,可联系管理员删除)
版权声明:网站转载的所有的文章、图片、音频视频文件等资料的版权归版权所有人所有。如果本网所选内容的文章作者及编辑认为其作品不宜公开自由传播,或不应无偿使用,请及时联络我们,采取适当措施,避免给双方造成不必要的经济损失。