写在前面
近日,在深度学习领域出现了一场热烈的争论。这一切都要从 Jeff Leek 在 Simply Stats 上发表了一篇题为《数据量不够大,别玩深度学习》(Don’t use deep learning your data isn’t that big)的博文开始。作者 Jeff Leek 在这篇博文中指出,当样本数据集很小时(这种情况在生物信息领域很常见),即使有一些层和隐藏单元,具有较少参数的线性模型的表现是优于深度网络的。为了证明自己的论点,Leek 举了一个基于 MNIST 数据库进行图像识别的例子,分辨 0 或者 1。他还表示,当在一个使用仅仅 80 个样本的 MNIST 数据集中进行 0 和 1 的分类时,一个简单的线性预测器(逻辑回归)要比深度神经网络的预测准确度更高。
这篇博文的发表引起了领域内的争论,哈佛大学药学院的生物医药信息学专业博士后 Andrew Beam 写了篇文章来反驳:《就算数据不够大,也能玩深度学习》(You can probably use deep learning even if your data isn’t that big)。Andrew Beam 指出,即使数据集很小,一个适当训练的深度网络也能击败简单的线性模型。
如今,越来越多的生物信息学研究人员正在使用深度学习来解决各种各样的问题,这样的争论愈演愈烈。这种炒作是真的吗?还是说线性模型就足够满足我们的所有需求呢?结论一如既往——要视情况而定。在这篇文章中,作者探索了一些机器学习的使用实例,在这些实例中使用深度学习并不明智。并且解释了一些对深度学习的误解,作者认为正是这些错误的认识导致深度学习没有得到有效地使用,这种情况对于新手来说尤其容易出现。
打破深度学习偏见
首先,我们来看看许多外行者容易产生的偏见,其实是一些半真半假的片面认识。主要有两点,其中的一点更具技术性,我将详细解释。
深度学习在小样本集上也可以取得很好的效果
深度学习是在大数据的背景下火起来的(第一个谷歌大脑项目向深度神经网络提供了大量的 Youtube 视频),自从那以后,绝大部分的深度学习内容都是基于大数据量中的复杂算法。
然而,这种大数据 + 深度学习的配对不知为何被人误解为:深度学习不能应用于小样本。如果只有几个样例,将其输入具有高参数样本比例的神经网络似乎一定会走上过拟合的道路。然而,仅仅考虑给定问题的样本容量和维度,无论有监督还是无监督,几乎都是在真空中对数据进行建模,没有任何的上下文。
可能的数据情况是:你拥有与问题相关的数据源,或者该领域的专家可以提供的强大的先验知识,或者数据可以以非常特殊的方式进行构建(例如,以图形或图像编码的形式)。所有的这些情况中,深度学习有机会成为一种可供选择的方法——例如,你可以编码较大的相关数据集的有效表示,并将该表示应用到你的问题中。
这种典型的示例常见于自然语言处理,你可以学习大型语料库中的词语嵌入,例如维基百科,然后将他们作为一个较小的、较窄的语料库嵌入到一个有监督任务中。极端情况下,你可以用一套神经网络进行联合学习特征表示,这是在小样本集中重用该表示的一种有效方式。这种方法被称作 “一次性学习”(one-shot learning) ,并且已经成功应用到包括计算机视觉和药物研发在内的具有高维数据的领域。
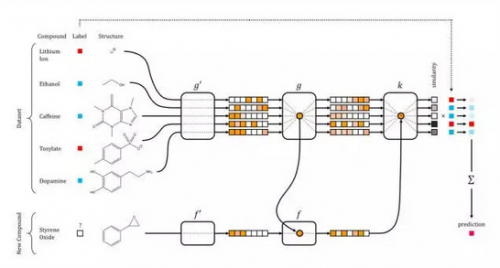
药物研发中的一次性学习网络,摘自 Altae-Tran et al. ACS Cent. Sci. 2017
深度学习不是一切的答案
我听过最多的第二个偏见就是过度宣传。许多尚未入门该领域的人,仅仅因为深度神经网络在其它领域的出色表现,就期待它也能为他们带来神话般的表现提升。其他人则从深度学习在图像、音乐和语言(与人类关系密切的三种数据类型)处理领域的令人印象深刻的表现中受到启发,于是就头脑发热地钻入该领域,迫不及待地尝试训练最新的 GAN 结构。
当然,这种大肆吹捧在很多方面是真实存在的。深度学习在机器学习中的地位不可小觑,也是数据建模方法库的重要工具。它的普及带动了诸如 tensorflow 和 pytorch 等许多重要框架的发展,它们即使是在深度学习之外也是十分有用的。失败者崛起成为超级巨星的故事激励了许多研究员重新审视以前的模糊算法,如进化算法和增强学习。
但任何情况下也不能认为深度学习是万能良药。除了“天下没有免费的午餐”这点之外,深度学习模型是非常微妙的,并且需要仔细甚至非常耗时耗力的超参数搜索、调整,以及测试(文章后续有更多讲解)。除此之外,在很多情况下,从实践的角度来看,使用深度学习是没有意义的,更简单的模型反而能获得更好的效果。
深度学习不仅仅是.fit()
深度学习模型从机器学习的其他领域传来时,我认为还有另外一个方面经常被忽略。大多数深度学习的教程和介绍材料都将模型描述为通过层次方式进行连接的节点层组成,其中第一层是输入,最后一层是输出,并且你可以用某种形式的随机梯度下降(SGD)方法来训练网络。有些材料会简单介绍随机梯度下降是如何工作的,以及什么是反向传播,但大部分介绍主要关注的是丰富的神经网络类型(卷积神经网络,循环神经网络等等)。
而优化方法本身却很少受到关注,这是很不幸的,因为深度学习为什么能够起到很大的作用,绝大部分原因就是这些特殊的优化方法(具体论述可以参考 Ferenc Huszár 的博客以及博客中引用的论文)。了解如何优化参数,以及如何划分数据,从而更有效地使用它们以便在合理时间内使网络获得良好的收敛,是至关重要的。
不过,为什么随机梯度下降如此关键还是未知的,但是现在线索也正零星出现。我倾向于将该方法看成是贝叶斯推理的一部分。实质上,在你进行某种形式的数值优化时,你都会用特定的假设和先验来执行一些贝叶斯推理。其实有一个被称做概率数值计算(probabilistic numerics)的完整研究领域,就是从这个观点开始的。随机梯度下降也是如此,最新的研究成果表明,该过程实际上是一个马尔科夫链,在特定假设下,可以看作是后向变分近似的稳态分布。
所以当你停止随机梯度下降,并采用最终的参数时,基本上是从这个近似分布中抽样得到的。我认为这个想法很有启发性,因为这样一来,优化器的参数(这里是指学习率)就更有意义了。例如,当你增加随机梯度下降的学习参数时,马尔可夫链就会变得不稳定,直到它找到大面积采样的局部最小值,这样一来,就增加了程序的方差。
另一方面,如果减少学习参数,马尔科夫链可以慢慢的近似到狭义极小值,直到它收敛,这样就增加了某个特定区域的偏置。而另一个参数,随机梯度下降的批次大小,也可以控制算法收敛的区域是什么类型,小的批次收敛到较大区域,大的批次收敛到较小区域。
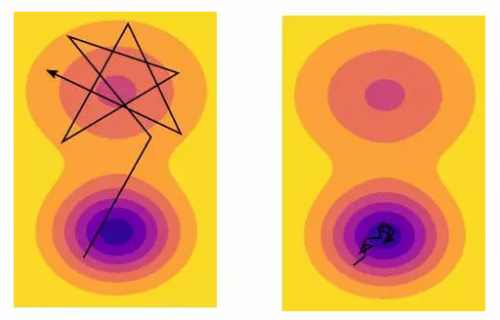
随机梯度下降根据学习速率或批尺寸来选择较大或狭义最小值
这样的复杂性意味着深度网络的优化器非常重要:它们是模型的核心部分,与层架构一样重要。这一点在机器学习的许多其他模型中并不常见。线性模型(甚至是正则化的,像 LASSO 算法)以及支持向量机(SVM)都是凸优化问题,没有太多细微差别,并且只有一个最优解。这也就是为什么来自其它领域的研究人员在使用诸如 scikit-learn 这样的工具时会感到困惑,因为他们发现找不到简单地提供.fit() 函数的 API(尽管现在有些工具,例如 skflow,试图将简单的网络置入.fit() 中,我认为这有点误导,因为深度学习的全部重点就是其灵活性)。
。 (本文来源网络整理,目的是传播有用的信息和知识,如有侵权,可联系管理员删除)
版权声明:网站转载的所有的文章、图片、音频视频文件等资料的版权归版权所有人所有。如果本网所选内容的文章作者及编辑认为其作品不宜公开自由传播,或不应无偿使用,请及时联络我们,采取适当措施,避免给双方造成不必要的经济损失。